|
La mise en œuvre et l’exploitation d’un
entrepôt de données dans un entreprise nécessite trois types de ressources : L’équipe de soutient technique, les
spécialistes d’entrepôt de données et les utilisateurs finaux.
L’équipe de soutient technique
L’équipe de soutient technique est celle qui
s’occupe des environnements de développement et de production et des serveurs. Elle voit à l’installation et la
gestion des bases de données, l’installation des serveurs Web et des outils d’exploitation. C’est dans cette
équipe que l’on retrouve le DBA qui doit travailler en étroite collaboration avec les spécialistes des entrepôts de
données.
Spécialiste d’entrepôt de données
Les spécialistes d'entrepôt de données ont les
connaissances des données et des systèmes informatiques permettant l’exploitation des données. C’est cette équipe
qui rend les données disponibles pour les utilisateurs finaux. Elle est responsable:
-
De définir le processus ETL où les données sont transformées de la banque de données opérationnelles à la banque
de données informationnelle afin de les rendre exploitables.
-
Administrer la couche d’accès à l’information pour rendre les données de la base de données accessible
à l’utilisateur final.
Les spécialistes de l'entrepôt de donneés de part
leurs connaissances uniques des données de la banque de données et du domaine d’affaires, sont à même de faire les liens
et transformations entre le système de saisit des données opérationnelles et le système d’exploitation des données informationnelles.
Transformation
des données opérationnelles en données informationnelles par l’ETL
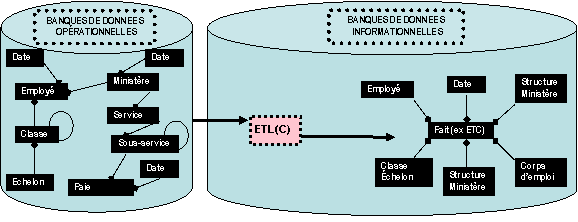
En effet la
banque de données opérationnelles est un système conçu afin de saisir rapidement
l’information unique : une transaction. Les tables de la base de données qui enregistre cette information sont
donc des objets de la plus petite taille possible afin de minimiser la grosseur de la transaction, un système de paie peu
compter quelques centaines de ces tables. Par exemple, lorsqu’une transaction de paie est enregistrée toutes les informations
connexes comme la structure administrative, les définitions de l’employé, les avantages etc. sont déjà enregistrés dans
des tables connexes. Il s’agit simplement de faire les liens, liens relationnelles qui se font dans les écrans de saisie,
afin d’enregistrer toute ces informations pour la paie de l’employé. Cette façon de faire favorise donc la rapidité
et l’efficacité de la saisit des données opérationnelles. Cependant elle rend difficile l’exploitation de grand
volume de données nécessaires à l’exploitation informationnelle.
Il faut transformer cette banque de données opérationnelle
en banque de données informationnelles. La banque de données informationnelles
est dénormalisée. C'est-à-dire que la multitude de tables de données opérationnelles sont agrégées en quelques tables informationnelles
qu’on appelle les dimensions et les faits. Les dimensions sont les axes d’analyse des données liées aux domaines
d’affaires connus par l’utilisateur par exemple : l’employé, la structure ministérielle et le temps
etc. Les faits sont de mesures comme la paie, l’absentéisme, l’ETC. Les faits sont analysés en les croisant avec
les dimensions. C’est ce qui donne un modèle en étoile qui permet de croiser rapidement les dimensions avec les faits.
L’ETL(C) (extraction, transformation and loading (chargement)) permet de
définir un processus de transformation afin de transformer les banques de données opérationnelles en banque de données informationnelles.
Le processus ETL est défini par les spécialistes de l'entrepôt de données et sera programmé lors de la mise en œuvre
du projet.
Une fois la base donnée transformée en étoile, il
est possible de relier cette étoile à un outil permettant de créer la couche d’accès à l’information ou même des
cubes OLAP. L’utilisateur final créé ces propres rapports en accédant cette couche d’accès à l’information.
Modèle en
étoile et couche d’accès à l’information
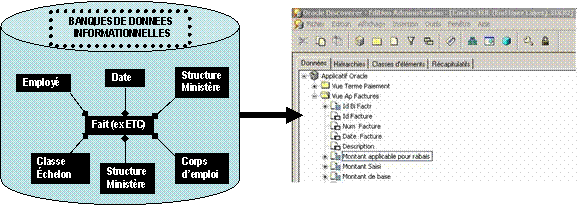
La couche d’accès à l’information sert principalement à transformer le langage informatique du modèle
étoile de la base de données en langage d’affaire propre à l’utilisateur. L’administrateur de la couche
d’accès à l’information fait l’arrimage entre ce langage informatique et d’affaire dans la couche
d’accès à l’information. La couche d’accès à l’information sert aussi à préparer pour l’utilisateur
final des choix pour le niveau d’agrégats, de hiérarchie, de filtre. Elle permet aussi de sécuriser les données par
la gestion de l’accès des regroupements de données en termes de domaines d’affaires. La gestion des privilèges
sur l’accès et les fonctionnalités disponibles pour l’élaboration de rapports y est aussi contrôlée.
Une fois que les spécialistes du SSRHRT ont rendu
les données disponibles via la couche d’accès à l’information, les données peuvent ensuite être exploitées par
les utilisateurs finaux.
Les spécialistes du SSRHRT doivent donc avoir les
outils nécessaires afin de consulter la base de données et les données qui y sont contenu. Ils doivent aussi avoir un outil
leur permettant de construire la couche d’accès à l’information.
Utilisateur final
L’utilisateur final se sert de la couche d’accès
à l’information afin de créer et distribuer ses rapports sous condition des accès et de privilèges accordé par l’administrateur
de la couche d’accès à l’information.
Couche d’accès
à l’information et outil d’élaboration de rapports
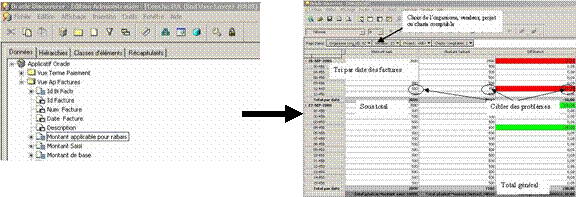
À partir de la couche d’accès
à l’information l’utilisateur final peut dans l’outil d’élaboration
de rapport choisir les éléments de données décrits dans son propre langage d’affaire afin d’élaborer ses rapports.
Il peut aussi faire des regroupements, tries, filtres, totaux, choisir entre différent type de présentation (matriciel, liste,
graphique), exceptions et formats etc.
Cet outil et ces fonctionnalités d’élaboration
de rapport doit-être disponible en mode web afin d’en facilité l’accès. L’utilisateur final peut y céduler
des rapports lourds qui s’exécuteront pendant la nuit. Il peut partager ses rapports aux utilisateurs et les distribuer
dans l’intra ou l’extranet. Il peut aussi les exporter en format texte, MS Excel, PDF et autres.
|

